马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?注册
×
Cerebras Systems在Supercomputing 2019上宣布了其新的CS-1系统。该公司于今年早些时候在Hot Chips推出了Wafer Scale Engine(WSE),该芯片采用了一整张300mm晶圆,将40万个内核,1.2万亿个晶体管,46,225平方毫米的硅和18GB的片上存储器的形式,全部集成在一个与整个晶圆一样大的芯片中,大到令人难以置信。再加上这款芯片耗电15千瓦,内存带宽为9 PB/s,毫无疑问,它是世界上最快的人工智能处理器。
推荐阅读:史上最大芯片及系统技术细节最新披露
一片晶圆仅做一颗芯片!1.2万亿个晶体管史上
最大芯片,是卫星还是创芯?
开发这种芯片是一项极其复杂的任务,但在一个合理的系统中,为所有计算出足够电力(更不用说足够的冷却能力了)的芯片提供电源则完全是另一回事。Cerebras已经实现了这一壮举,今天该公司宣布推出世界上最快的深度学习计算系统 Cerebras CS-1 。并且公布了系统内部的详细设计图。
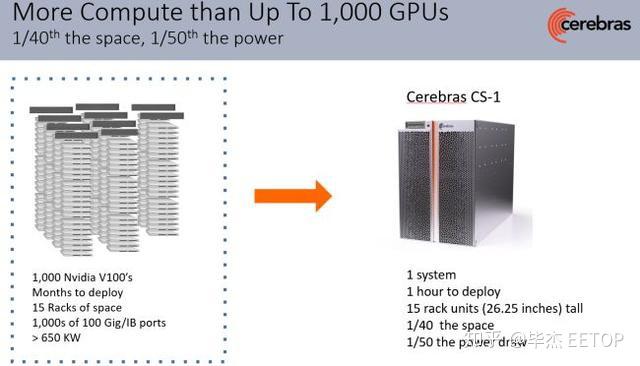
该系统高度为15U,大约为26英寸,因此三个系统可以装在一个机架中。考虑到性能,这是一个非常紧凑的封装:它包含了1,000个GPU的集群,50千瓦的功率,以匹配一个CS-1系统的性能,这是因为单个Cerebras芯片的内核数量是单个GPU的78倍以上,内存是3,000倍,内存带宽是10,000倍,此外它还具有33000倍的带宽(PB/s)。
(图片来源:Cerebras) 一套谷歌TPUv3 Pod功耗为100KW,但只有1/3的单个CS-1系统性能。总体而言,单个CS-1的功耗仅为其1/5,尺寸仅为其1/30,但比整个TPU POD快了三倍。
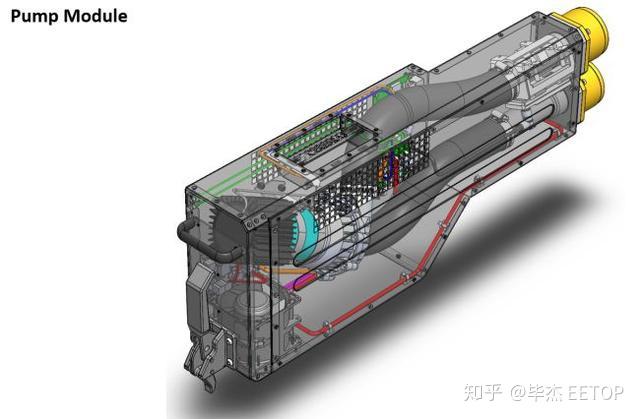
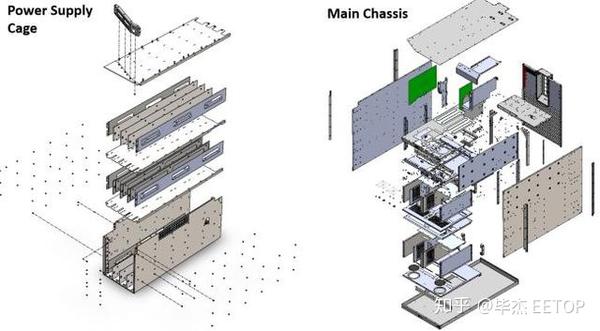
相比之下,单个Cerebras CS-1消耗20kW,其中4kW的功率专用于冷却子系统,例如风扇,泵和热交换器。该系统为芯片提供15kW的功率,而剩下的1kW因电源损耗。 系统左上角有十二个100GbE连接。这些系统将与执行传统形式的计算的大型超级计算机协同工作。然后,由超级计算机处理的数据将流入CS-1进行其他AI处理,从而利用两种类型的计算的优势来满足不同的工作负载。该系统还可以通过网络结构扩展到多个节点,这意味着CS-1系统可以在更大的组中工作。Cerebras测试了“非常大”的集群,然后可以在数据并行模式的模型并行中将其作为单个同构系统进行管理,但尚未发布官方的可伸缩性指标。 整个Cerebras CS-1由定制组件组成。系统通过十二个电源连接从后部获取电源。然后将其从54V降低至0.8V,然后把它送到芯片上。电源通过主板(而不是围绕主板),然后进入处理器,不同的区域有不同数量的内核,每个内核接收自己的电源。晶圆级芯片由许多管芯(单元裸片)和管芯网络结构捆绑在一起组成,功率传递比管芯/标线片闪存更为精细。这确保了整个晶片上一致的功率传输,并且还最小化了片上功率分配平面。
这是一个三明治式设计,具有电源子系统,母板,芯片和冷却板作为一个组件安装(左)。冷板从歧管向右接收冷却水,然后将冷水输送到冷却板表面上的几个单独区域。然后,再次从确保一致散热的小区域抽取热水,将其抽到设备底部的热交换器。该交换器由EMI格栅组成,并由采用空气矫直机的强力风扇冷却。总体而言,该芯片的运行温度为标准GPU的一半,从而提高了可靠性。 所有单个单元(例如6 + 6电源,热泵,风扇和热交换器)都是冗余的,并且可热交换,以最大程度地减少停机时间和故障。 该芯片是在台积电的16纳米工艺上制造的,由于其成熟度和产品发布的时间安排,该公司选择了该芯片。Cerebras尚未指定主频速度,但告诉我们该芯片的运行时钟不是非常“激进”的(该公司定义为2.5GHz至3GHz的范围)。该公司将在不久的将来提供详细信息。
Cerebras尚未指定该产品的定价,据悉将会是几百万美元。在面向公众的方面,阿贡国家实验室正在将第一套系统用于癌症研究和基础科学,例如研究黑洞。Cerebras已经建立了一个软件生态系统,该部门可以接受标准的PyTorch和TensorFlow代码,这些代码可以通过该公司的软件工具和API轻松修改。该公司还允许客户指令级访问芯片,这与GPU供应商不同。
|  /2
/2 


 eetop公众号
eetop公众号 创芯大讲堂
创芯大讲堂 创芯人才网
创芯人才网
 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2019-11-20 15:26:23
发表于 2019-11-20 15:26:23









 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 发表于 2019-11-23 23:43:47
发表于 2019-11-23 23:43:47

 创芯人才网
创芯人才网