马上注册,结交更多好友,享用更多功能,让你轻松玩转社区。
您需要 登录 才可以下载或查看,没有账号?注册
×
如果给人类一个机会,让人类重新设计计算机网络,大概人类不会把网络设计成现在这个样子。 电话,电报与分组交换
在互联网最初被设计出来的年代,设备工作的很慢,计算机也很慢,能用网络发送一下电子邮件就已经很让人觉得了不起了,实际上互联网被设计出来也是这样的目的。在互联网出现之前,人类运用电的通信手段其实已经有两种了,一种叫做电话,一种叫做电报。 电话的工作原理,如果看过老电影的话会比较容易了解,那个时候电话不用拨号,要打电话的人拿起电话,对面是接线员,他会对接线员说:帮我接通XXX。接线员会在一堆接头中找到两根线,把两根线插到一起,于是两部电话就通过电路连接了起来,两边的人就能通话了。如果全靠人工接,那要打个国际长途可累死了,一个一个接线员报地址,一根一根接,所以后来发明了电话交换机。当拨号方拨出号码的时候,电话局的程控交换机自动将对应的线找出来然后接通,一路接到被叫的一方。当被叫一方拿起电话的时候,两个人的通话通过一根完整的电路回路相互接通,语音通过模拟信号在两人之间传递。它的特点是通信的双方之间一定有一个独占的信道,哪怕拿起电话谁都不说话,让沉默在线路上蔓延,这条信道也是双方独占的,电话局也会在这沉默而略显冷清的气氛中,默默收取着电话费。因此它的通信代价是比较高昂的。 电报则与电话不同,它通过有线或者无线将比较短的整段消息发送给接收方。通常发送和接收方会使用相同的信道,比如某个特定的无线电频率,有要发送的消息的时候,发报员就会按动开关发出滴滴的长短音莫尔斯码,对方一个戴着耳机的发报员就会紧张地在纸上刷刷刷写着内容。虽然不发送消息的时候不会占用信道,但一旦开始发送,这个消息是不能中断的,必须发完才能发下一封,所以发电报一般都要求尽量简短,如果一个人去邮局说“把这本唐诗三百首”拿电报发给我儿子,工作人员一定会用MDZZ的眼神来看着他:发你电报的过程中,其他电报可是发不出去的,有紧急的电报来了,一问,发报员说“你等等,我刚发完杜甫的‘无边落木萧萧下’,离李商隐的‘相见时难别亦难’还有一百多年呢”,这不得疯。而且不同的人发电报不能占用相同的信道,不然就串线了,谁也收不到正确的内容。 这两种通信方式都明显不适合计算机之间的通信。互联网中,计算机随时有可能跟另外任意一台计算机通信,如果你用电话形式的网络,计算机发一次消息就要占一条线路,同时发的多了一下就把线路挤爆了,成本上也接受不了;用电报形式的网络,一台计算机发了个非常长的报文,所有的计算机都得停下来等着,这也不行。所以人类设计出了分组交换的方法,发太长的报文不行,那一次只发一小段,要发内容多你就拆成一小段一小段发出去。这构成了互联网最重要的基础。在这之上,人们会想,我应该用分组交换发送什么内容呢?人终究是缺乏想象力的,一拍脑袋,我就发两种,一种模拟电话,一种模拟电报。模拟电话的,在发送方和接受方之间建立一个逻辑连接,然后像打电话一样连续、可靠地传输数据,也叫做虚电路;模拟电报的,将一个很长的报文拆成很多个分组,发到对面再重组起来变回一个长报文,叫做数据报。 今天我们知道了,虚电路就是我们常用的TCP协议,而数据报则是UDP以及ICMP等协议。 TCP/IP协议栈
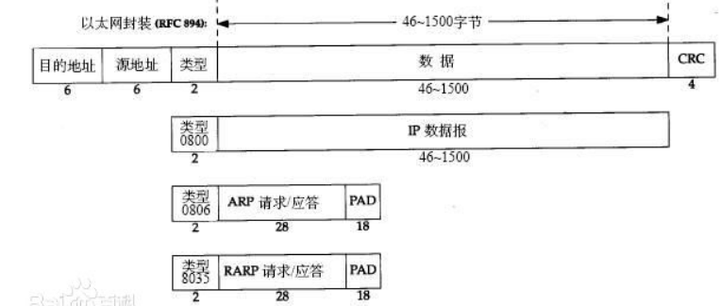
有了交换方法,我们还得规定确定发送方和接收方的地址的手段,就好像电话要有电话号码一样。IP网络中使用IP地址来确定发送方还是接收方。这个IP地址设计的也跟电话号码很像,我们知道电话号码要先拨国际区号、再播区号、最后才是本地号码,不同号码会给不同级别的电话交换机的接线提供信息。IP地址的设计也是这样,最早IP地址的子网范围是固定的,4个字节合计32位的IP地址,最高位为0的是A类地址,子网范围有24位,最高位是10的是B类,子网范围有16位,110的是C类,子网范围有8位,1110的是D类,没有子网范围了,自然不是正常的IP地址,它们被用来做广播地址。这个设计是个大坑,A类地址最多占了总IP地址的大约50%,却只被分成了一百多个子网,每个子网的IP数量多达一千六百多万,美国几个单位一分全分完了;B类地址每段只有六万多个,C类更是可怜,每段只有254个。美国把中国喊过来说,中央已经研究决定了,以后你们中国就用这段C类地址,中国一定心想:MDZZ,这还不够中南海用的。所以后来撤销了类的概念,可以将许多个C类合成一个大段分配,也可以将A类或者B类拆分成小段分配,现在分配的IP段都是这样的,但不管怎么说,IP地址分为左边若干位的子网网络地址(相当于总台号),和右边剩下位的网内地址(相当于分机号),这个算是定了下来。 然后人们会发现,我TCP也需要这个地址,UDP也需要这个地址,不如就提供一套地址就好了。这就出现了协议分层和协议栈的概念。从这就明显可以看出,当年的网络显然是由软件工程师来设计的,充满了软件的设计理念。毕竟当年的硬件只有两种,一种是计算机,一种是计算机输入数据的板卡。对于软件工程师,尤其是那个年代的软件工程师来说,写代码太累,没有什么比让代码重用更重要的事情了,所以能分层的都要尽量分个层出来,层之间的协议相互调用,于是软件代码可以达到最大程度的复用,以后开发新的协议也会比较简单。OSI参考模型甚至将网络分成了七层:物理层,数据链路层,网络层,传输层,会话层,表示层,应用层。也就是我们常说的L1, L2, L3, L4, L5, L6, L7。 由于TCP/IP的大量使用,实际上L5、L6的协议栈中并没有相应的协议,几乎所有的L7协议都是直接实现在L4的上层。这样对于实际应用中的网络来说,通常是L1,L2,L3,L4,L7五层,这其中的L1是直接跟电路相关联的,它使用专用的硬件电路来进行编码解码,因此对于我们来说实际可见的是L2,L3,L4,L7这四层。 我们一层一层的来说。目前的网络中最广泛使用的L2(数据链路层)协议毫无疑问是以太网。以太网在物理层很有讲究,但在数据链路层结构其实是很简单的:
源和目的地址是MAC地址,MAC地址是6字节的硬件地址,我们一般看到的像30-65-EC-74-59-2B(Windows)或者30:65:ec:74:59:2b(Linux)这样的用16进制表示的就是,它一般是网卡出场时候就选定的全球唯一的地址。以前的以太网是以一种广播的形式将数据包发送给子网内所有的机器的,把目的MAC地址放在前面,可以让接收方迅速判断某个数据包是不是发送给自己的。我们可以看到,这层协议的格式中只包括了最最必要的内容,没有任何多余,这种简洁也是它流行起来的重要原因。
对于数据中心之类的地方,通常希望即使在同一套物理网甚至同一个交换机上,也可以允许不同端口像在不同交换机组上一样互相隔离,因此引入了一种新的帧格式叫做802.1q,或者VLAN:
它比普通的以太网帧多了4个字节。首先前两个字节保持原意,代表上层协议类型,但这里是0x8100,表示使用VLAN;紧接着3bit的PRI,1bit的CFI,12bit的VID,PRI是优先级,CFI永远为1,真正有意义的主要是VID,它就是我们说的VLAN号,相同VLAN号的帧相当于运行在同一个二层网络中,而不同VLAN号相当于不同二层网络,相互隔离。后面再跟一个上层协议类型字段,这个字段才是真正的上层协议类型。
以太网帧传输的上层数据有大小限制,这是因为最初以太网被设计为在共享介质上传输数据,如果帧太长,就会出现前面说的发送电报的情况,违背了分组传输的设计。一般这个大小被设计为1500字节,也叫做MTU。注意MTU的计算方法,它是不包含L2帧头的,也就是只有图中“用户数据”那一部分计算大小。考虑到以太网帧头,实际的L2包长要额外增加14(无VLAN)或18(有VLAN)个字节,再加上4字节的包尾CRC。在物理层上还有一些额外的开始结束信号,不过对上层来说可以不考虑。
L3主要传输用户数据的协议是IP和IPv6,其他还有IP地址解析使用的ARP等。重点说IP,IP的帧头格式是这样的:
它的字段就要多得多了,也是非常复杂的一层,它支持以下的功能:
- 它可以添加若干个可选项,因此包头本身就是变长的。在第一个字节的IHL部分保存了整个包头的长度。所有IP参与者都要正确实现所有IP选项这一点真的有点痛。
- 它是可以分片的。因为分层,IP层无法假设上面的协议发送了多长的数据,也无法假设下层的协议究竟支持多长的数据,如果上层数据长度相对底层支持能力来说过长,则会在这一层将数据包分片,在到达目的地时重组。分片的包在传输中可能被进一步分片,这也是IP层协议最复杂的地方。
- 它的包头有独立的checksum,保证传输不出错。
IP报文可以分片,这是IP层协议的一个重要特性。按IP层规定,每个分片中最少要传输8个字节的上层协议内容,这样如果上层协议的包头比较小,它应该可以包含在第一个分片当中。然而现实是残酷的,我们继续来说L4协议。
L4是IP层上层的传输层协议,最常见的是TCP、UDP、ICMP,但也有GRE、IPSec中使用的ESP与AH协议、IPv6 over IPv4等其他协议。TCP是其中比较复杂的一种协议:
TCP实现了可靠传输,可靠传输的机制非常复杂,在各种计算机网络教材中都有涉及(然而大多数都没有讲完整,因为完整机制太复杂),这里不再细说。TCP传输数据流,数据流天生是分段的,这跟IP层的分段能力重复了。
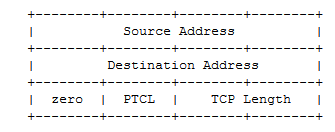
TCP通过MSS(Max Segment Size,最大分段大小)协商来避免分段,方法是将MTU - 40(IP包头最少20字节,TCP包头最少也是20字节),由于以太网MTU为1500,因此一般选择的MSS为1460。注意这还不是真正传输的数据分段的大小,由于20字节只是IP和TCP包头的最小大小,而IP包头可以有选项,TCP包头同样可以有选项,实际传输的分段要使用MSS + 20 - IP包头大小 - TCP包头大小来计算,这个计算无情地打破了协议分层的设计,是一种丑陋的hack。 即便如此,TCP也只是尽量避免了分片,而不是不可能分片,TCP报文仍然可能在中途被IP传输设备进一步分片来适应中途的比较小的MTU,因此IP段的报文重组仍然是可能发生的。悲惨的是TCP的包头有20个字节以上,因此连包头也是有可能被分片的,第一个报文当中有可能仅仅包含端口号,连非常重要的TCP标志位也可能被分片到后面的段当中。 TCP的整个分段都有checksum校验,来保证数据的正确传输。而且这个checksum的计算不仅仅包括整个L4协议数据,还包括了一个称作伪头的虚拟数据,这段数据不在真实的报文中传输,因为它其实是4层以下的部分包头信息的校验和:
设计这个校验和的初衷是防止报文被转发到错误的地点然后被错误的人接收,然而IP头也有独立的校验和,其实挺意义不明的,而且在今天的网络中,我们每天都在通过NAT(Network Address Translation)的技术特意去修改IP地址和端口号。
UDP的报文则比较简单:
包头刚好8个字节,保证在第一个分片中传出。UDP也有校验和,使用整个报文进行计算,同样也加上类似于TCP的伪头,但由于本来就是不可靠传输,在IPv4中也可以忽略校验和。UDP报文长度可以超过MTU,使用IP层的分片功能进行分片和重组。如果进行了分片,后续被分片的报文中是没有UDP端口信息的。这就给NAT技术带来了很大困难。
第三种重要的L4协议是ICMP,我们常用的ping就是ICMP协议中Echo/Reply的应用。ICMP协议比较简单,但是,ICMP协议是IP协议层的控制协议,意味着它会反过来影响第三层的工作,或者跟第三层互动,比如说IP转发失败的时候回复ICMP消息, 甚至使用ICMP协议来控制路由(现在不常用),对于要正确处理网络协议的设备来说也是个令人头疼的协议。 L7就很丰富了,HTTP、FTP、SSH等基于TCP的,DHCP、DNS等基于UDP的,协议五花八门,不再赘述。我们今天要说的主角OpenFlow协议——这主角怎么还没出场—— 也是一种基于TCP的L7协议。然而还没到它出场的时候。 交换技术设计之初,网络的运行都是基于计算机系统的,包括网络设备,因此是软件工程师主导。但是互联网爆发式发展之后,使用软件的路由和转发技术遇到了严重的瓶颈。现在的互联网不像当初只是为了发发电子邮件、传传小文件、偶尔看看纯文本的Web和RSS,而是有数十亿用户、海量的多媒体数据相互传输的巨无霸系统,骨干网的传输能力需要达到TB级别。基于软件的路由转发很难做到很高的吞吐量,即便增加CPU、内存,软件转发的延时也是个大问题,当转发次数增加的时候,数据包的延时不断增加,网络很快就会变得不堪使用,想一下如果你的数据包传到服务器需要一秒的延时,你还能愉快地打dota吗? 除此以外,对网络转发功能的需求也在与时俱进。由于糟糕的IP分配策略,全球IPv4资源分分钟要耗尽,大量的个人和商业网络使用私有网络地址并进行NAT转换,来达到访问公网的目的,NAT技术通常需要在转发时对四层以上的包头进行操作;为了网络和服务器的安全性,防火墙、IDS/IPS等系统需要深入到网络数据的L4甚至L7层来进行检测和过滤。这些都不是基于计算机软件的交换系统所能承受的。 当软件工程师一筹莫展的时候,就到了硬件工程师大展身手的时候了。ASIC,专用集成电路,这项技术的发展给了互联网新的契机。最早,交换技术仅仅是以太网中的一种技术,用它替代以太网中坑爹的共享介质,可以大大提高较大规模二层网络中的数据传输效率,减少冲突发生。很快人们就想到,既然这种技术这么有效,那么用来解决三层甚至四层上的问题,也是可以的吧? 首先我们来讲讲硬件交换的原理。与软件不同,硬件交换使用专用的集成电路进行,它可以根据需要具有同时处理许多个二进制位的能力,只需要有足够的组合和时序逻辑元件就可以。虽然网络协议是分层的,但是在实际使用中,绝大多数情况下,我们需要大量转发的报文中,只有一种二层协议——以太网;只有少数几种三层协议——IPv4,IPv6,ARP;只有少数几种四层协议——TCP,UDP,ICMP。我们可以将这些协议的包头的组合拼到一起,变成一个完整的序列,比如TCP: 【目的MAC】【源MAC】【以太网类型】(【VLAN_TCI】【以太网类型】)【IP包头与长度】……【IP源地址】【IP目的地址】……【TCP源端口】【TCP目的端口】…… L2,L3,L4各自的包头都是可以变长度的,这带来一些复杂度,不过并不要紧,相应的长度都可以用简单的组合逻辑计算出来,于是我们可以用一个时钟周期,使用专用的电路,从数据包中读取到我们需要的所有的字段。 接下来,我们把我们要进行的转发,都用统一的方法描述出来: 目的MAC = xxx,转发到XX号端口; 源MAC = xxx,目的MAC = xxx,进行广播; 目的MAC = xxx,目的IP = xxx,修改源MAC = xxx,目的MAC = xxx,TTL = TTL - 1,送去XX端口; 目的MAC = xxx,VLAN ID = xxx,目的IP = xxx,TCP端口 = xxx,修改目的IP = xxx,TCP目的端口 = xxx,TTL = TTL - 1,修改VLAN ID为xxx,送去XX端口。 这其中的每条规则特点都是匹配若干个字段(不区分L2,L3,L4),执行某些操作(通常是修改某个字段的值或者转发到某个端口)。如果可以跟这些规则匹配,数据包就可以不经过软件处理直接转发到相应的端口,甚至从接收到包头就可以开始转发,后续的数据报文可以直接从一个端口通过逻辑电路传输到另一个端口上,这样端口之间同时进行的转发不会占用相同的资源。除此以外,也一定会遇到硬件无法单独处理的情况,这时候硬件转发设备会使用传统的方法,转发设备内部都有CPU和内存,有操作系统,实际上也是一台计算机,硬件会通知计算机内的软件来对它无法处理的数据包进行软件处理,软件根据处理结果指示硬件如何进行转发,或者调整硬件转发的规则。 使用ASIC交换技术之后,网络设备的吞吐量大大增加,延迟大大降低,现在的主流网络设备中,单块板卡的L3交换能力可以高达40Gbps,而延迟小于1us。正是这种技术使得国际互联网可以有机会发展到今天的规模。 控制转发分离与OpenFlow千呼万唤始出来,我们今天的主角(?)OpenFlow协议,就是继承上面的多层交换技术思想的。当然首先它是一个TCP协议,有一套wire protocol,用来分割和解析二进制消息,这不是今天要讲的重点。今天要讲的重点是它的思想,以及它怎么控制交换机。 OpenFlow使用的、对交换机最基本的控制功能叫做流表。流表就是我前面所说的规则,它由流(Flow)组成,以不区分协议层级的方式,直接匹配数据包的包头,并执行相应的操作。一般来说,一条流(Flow)有以下部分组成: - 匹配条件,也就是“MAC地址等于XXX,IP地址等于XXX”这样的一系列要求。所有的要求必须同时满足才会匹配到这一条规则。它可以很容易在硬件中翻译成可编程逻辑,以非常高效的方式与数据进行匹配。除了完整值的匹配,许多字段还支持带掩码的匹配,比如说可以匹配所有的组播MAC地址(组播MAC地址的第一个字节的最低位是1,也就是说必须匹配01:00:00:00:00:00/01:00:00:00:00:00,前一个是值,后一个是掩码),可以匹配IP段(比如192.168.1.0/255.255.255.0,前一个是值,后一个是掩码)。
- 执行的操作。当发生匹配时,对数据包进行一系列的操作,主要可以进行的包括:修改字段的值;增加或删除VLAN包头;输出到指定的端口;上传给控制器等等。如果修改某个字段影响了checksum的计算,checksum会自动被更新到相应的值。由于checksum的计算是线性的,这个更新非常高效。
- 优先级。当多条流同时匹配某个数据包时,只有优先级最高的一条生效。
- Table ID,流表编号。这是OpenFlow 1.1+开始的新功能,现在已经普遍被支持。我们可以将匹配规则放到不同的表中,然后串联起来执行:第一个表中执行的结果可以送到第二个表中继续,第二个表中可以送到第三个表或者直接跳转到后续的其他表,也可以随时选择中止执行。这样大大增加了流表的功能和表述能力。硬件上,这样的结构可以使用pipeline技术来高效实现,不会降低转发性能。每条流中可以指定下一个处理的流表,或者选择不进入下一个流表,直接停止执行。
- 有效时间。这是个很有用的选项,它来源于许多现有的技术,比如以太网交换的学习机制,比如ARP地址的缓存等等,它可以让流只在一段时间内生效,这样就可以利用学习机制不断添加新的流,而旧的、失效的流会自动被清理掉。超时分为两种,分别称为硬超时(hard timeout)和空闲超时(idle timeout),前一种是流到了时间固定被清除(除非通过修改流来更新这个时间),后一种是流超过一段时间没有被用到则被清除。
- Cookies,这是个OpenFlow管理用的概念,与交换无关,控制器可以用Cookies来标识某条特定的流,这样后续删除或者修改的时候可以很方便指定这条流。
流的概念直接对应到了交换机中的ASIC交换芯片的功能,允许控制器绕过交换机配置,直接设计这些功能。 我们前面也说了,由于网络协议的复杂,并非所有的数据包都可以完全由流表来处理,在流表无法直接处理时,可以通过流表将数据包上传给控制器。控制器通过PACKET_IN消息收到这个数据包,与我们在网卡上收到数据包不同,这个包被封到了PACKET_IN消息中,还附带了许多有用的流水线信息,比如说包来自于哪个端口,前面的流表使用了哪些字段等等。控制器通过纯软件方式处理这个数据包,处理之后一般可以有三种选择: - 使用PACKET_OUT消息,将数据包直接发往某个端口
- 修改流表,并告诉交换机重新对这个包进行处理
- 丢弃这个包
通过PACKET_IN/PACKET_OUT机制,OpenFlow协议将传统交换机中仍需要软件处理的部分,移到了交换机之外,由控制器进行处理。这样交换机内部的操作系统只需要能正确处理OpenFlow协议就够了,支持的功能可以通过升级控制器来增加和修正。这就是OpenFlow的控制与转发分离的思想。OpenFlow交换机的控制功能完全移交给了控制器,转发功能通过可编程的ASIC进行,用很简单的结构就可以满足高速高效的交换需求。 如果重新设计网络……如果人类能有个机会重新设计网络,也许不会设计成现在这个样子。当然这恐怕不是我说了算的事情,但是也许…… - 也许二层协议有一种就够了,一种类似于以太网帧的,定长的,带有VLAN ID的格式。VLAN ID占全部的16个bit,4096个真的不太够用。支持的MTU至少有1500。有Overlay需求的,需要根据Overlay的层数增大MTU。
- 也许三层协议只需要一种就够了,地址使用IPv6,但是包头简化,定长,不支持分片。
- 四层协议也许只需要两种,一种是有连接,一种是无连接,都像TCP一样每个分段都包含完整的协议头,协议头不允许被分片。所有的变长选项都出现在四层中。
- 四层以上可以再次堆叠二层、三层或者四层包头,形成Overlay的隧道。
由于二层三层只有一种协议而且都是定长的,实际上我们取消了协议的分层,只保留了一种协议,它有两个可能的变种。如果这样设计,ASIC交换将会大大简化。然而历史不可能重来,如何在现有的网络基础上进一步挖掘潜力,这正是网络研究要解决的问题,也是SDN考虑的方向。
|  /1
/1 


 eetop公众号
eetop公众号 创芯大讲堂
创芯大讲堂 创芯人才网
创芯人才网
 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2020-9-29 09:36:33
发表于 2020-9-29 09:36:33




 提升卡
提升卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡
 创芯人才网
创芯人才网